Web scraping techniques have evolved significantly, particularly with the increasing prevalence of server-side rendered (SSR) websites. Traditional scraping methods involving CSS selectors are being replaced by AI and large language models (LLMs) for more efficient data extraction. Additionally, the use of proxy networks has become essential to avoid detection and blocking when accessing this data. New strategies include leveraging APIs directly from fetch requests where available and utilizing embedded JSON data within SSR web pages to access structured data more conveniently.
Proxies are now essential for web scraping due to increased detection measures.
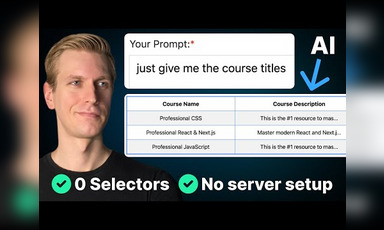
AI and LLMs are transforming web scraping methodologies.
SSR websites render data on the server, complicating traditional scraping methods.
Extracting JSON from embedded scripts can yield additional data in SSR setups.
The integration of LLMs into web scraping signifies a shift in data processing methodologies. This allows for deeper insights into unstructured data by leveraging AI's capacity to understand context. Moreover, as websites increasingly adopt SSR, data scrapers must adapt by using techniques like extracting embedded JSON data that may reveal hidden insights, which traditional scraping methods overlook.
With the growing complexity of web scraping, ethical considerations are paramount. The use of proxy networks raises questions about data ownership and privacy. Furthermore, the evolving landscape of SSR technologies requires scrapers to remain compliant with legal frameworks and ethical standards to ensure responsible usage of data while respecting website terms of service.
This method enhances performance by delivering a fully rendered page, which complicates traditional data scraping techniques.
LLMs streamline the data extraction process by interpreting complex web data efficiently, especially when traditional scraping methods fail.
The use of proxies helps avoid detection and blocking by websites that implement anti-scraping measures.
Data Impulse provides rotating IP addresses, allowing users to scale their scraping efforts without facing blocks.
Mentions: 5