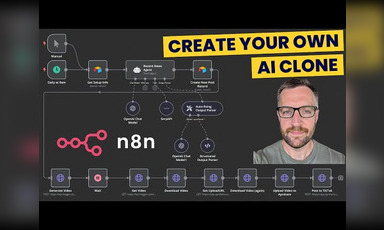
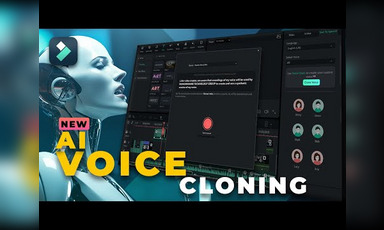
Voice cloning technology is showcased through a local model using the Pinocchio framework, demonstrating impressive quality. This model requires a high-quality input voice and allows for the customization of text-to-speech outputs. Comprehensive details about Hugging Face's resources and TTS models E2 and F5 are shared, along with ethical considerations regarding voice cloning applications. Additionally, the speaker emphasizes that the technology supports multiple languages, notably Chinese, and suggests practical uses like podcast generation. The demo highlights both the capabilities and limitations of current AI voice synthesis technology.
Introduction to advanced voice cloning and quality dependency on input voice.
Discussion on the Hugging Face models F5 and E2 and their capabilities.
Showcasing AI's innovation in podcast generation with synthesized voices.
Explaining the technical setup and prerequisites for using the Pinocchio model.
Voice cloning technology raises significant ethical concerns regarding consent and misuse. Ensuring that synthesized voices are used responsibly is crucial, especially with the potential for deepfake misapplications. Continuous dialogue among developers, users, and law-makers will be necessary to establish guidelines that prevent exploitation.
It is emphasized to be significantly quality-dependent on the input voice used for training.
The speaker discusses F5 and E2 models for generating fluent speech.
It is used to run high-quality voice synthesis tasks locally on computers.
The video illustrates its contributions to TTS and voice synthesis technologies for various applications.
Mentions: 5
Neil Stephenson | No-Code AI & Automation 10month