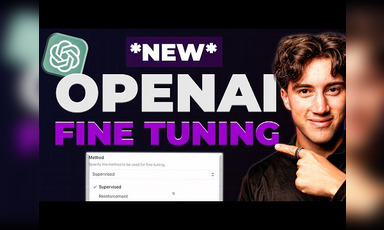
AI reasoning models like O3, Gemini, and others are being developed to provide clear insights into their decision-making processes. The focus is on creating reward models that not only assess the final outcome but also track the progression of reasoning through complex problems. This dual approach encourages continuous learning and adaptation as AI interacts with various reasoning paths. New methodologies like the meter reinforcement fine-tuning framework are introduced to further optimize AI performance by balancing exploration and exploitation while minimizing cumulative regret during inference.
AI reasoning models analyze decision-making processes to enhance problem-solving.
New reinforcement learning models emphasize exploration versus exploitation balance.
Cumulative regret term is introduced to improve AI learning efficiency.
Comparison of methods indicates the relevance of reinforcement learning in AI advancements.
The introduction of cumulative regret in AI systems represents a significant shift towards more accountable and transparent AI practices. By measuring the performance against an ideal model, organizations can better assess their AI capabilities and mitigate risks associated with AI decision-making. This approach fosters trust as it emphasizes continuous learning and adaptation in complex environments. Companies adopting these frameworks must ensure that ethical considerations are integrated into the design and evaluation of AI systems.
The video highlights the importance of balancing exploration and exploitation in AI development, particularly in reasoning models. Implementing the meter reinforcement fine-tuning framework shows promise in optimizing decision-making and improving model performance in real-time. As data scientists, it's critical to monitor the cumulative regret metrics to fine-tune our models effectively. Furthermore, the focus on detailed performance metrics encourages iterative improvements, which can lead to significant advancements in AI applications across various industries.
It is a crucial metric in evaluating reinforcement learning methods to optimize decision-making processes.
It balances exploration and exploitation while minimizing cumulative regret, leading to improved reasoning.
The AI reasoning models discussed help uncover insights into how AI approaches challenges.
The collaboration with Google Research has led to significant advancements in AI reasoning techniques.
Mentions: 2
Their recent studies are shaping methods for enhancing AI performance.
Mentions: 5